
Just-in-Time Context,一篇就够了。¶
READ⏰: 35min
☁️ Thinking in Context
距离上一篇博客已经过了许久,前段时间一直在读一些技术无关的书籍,最近终于重新开始写一些东西。
本篇结合最近阅读的博客、使用 Agent 产品的体验,谈一谈上下文工程中的一个关键范式转移:从 LLM 被动接收上下文,到 Agent 主动获取上下文(Just-in-Time Context)。
内容主要包括:
- Recall:重温并拓展 Context Engineering 的 What & Why?
- JIT Context:什么是 Just-in-Time Context(我觉得也可以叫 Agentic Context),以及为什么需要它?
- Effective JIT Context Engineering:JIT 的代价,以及如何通过 Compress / Write / Isolate 实现高效的上下文管理。
算是上一篇博客的深入,信息量略大。很多是我自己的思考,欢迎指正~
1. Recall & Introduction¶
在上一篇《Context Engineering,一篇就够了》中,我主要介绍 Context Engineering(上下文工程)的概念和定义,包括它与 Prompt engineering(提示词工程)的区别。在我写完这篇博客不久后,Anthropic 的一幅图可以帮助大家更准确的理解它们之间的区别(一图胜千言):

简单的回顾一下它们的定义,提示词工程是为了获得最佳推理结果而编写和组织 LLM 指令的方法,上下文工程则是指在 LLM 推理过程中,动态规划和维护最优的输入 token 集合(集合包括任何可能进入上下文的信息)。
继续回顾下为什么上下文工程如此重要,在之前的博客通过两个例子来证明其重要性。本篇可以补充一些更学术性的说明。有关上下文腐烂(context rot)的研究表明:随着上下文窗口中 tokens 数量的增加,模型从该上下文中提取准确信息的能力会相应减弱(上篇博客中的“上下文退化”章节也其实暗含了这个结论)。虽然某些模型的性能衰减相对平缓,但这种现象在所有模型中都普遍存在。因此我们需要把上下文视为边际效益递减的有限资源(如上篇博客中把上下文窗口比做计算机系统中的内存)
Anthropic 在博客中提到:如同人类的工作记忆容量有限,LLM 也拥有所谓的“注意力预算”,在解析长上下文时会消耗这一资源,每一个新引入的 token 都会占用一定的预算。这就更加突显了上下文工程的重要心,即动态规划和维护最优的输入 token 集合,不浪费注意力预算。这种注意力(Attention)的稀缺源自 Transformer 架构的限制,Transformer 允许每个 token 去关注整个上下文中其他所有 token,这就意味着对于 N 个 token,将会产生 N^2 个两两交互的关系。
随着长度增加,这种指数级的交互需求导致注意力不可避免地被“稀释”。加之训练数据中长序列的天然稀缺,以及位置编码插值带来的感知模糊 [1],模型在处理长上下文时性能会呈现出梯度式的衰减——即虽未崩溃,但在长程检索与推理的精度上已大打折扣,而 agent 架构不可避免的引入长上下文(“In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats. ” —— Anthropic [2])。这也是上下文工程存在的根本意义:对抗这种架构性的边际收益递减,构建强大的 Agnetic system。

除了简单的介绍上下文的定义和重要性外,如图所示在上一篇博客中,我们试图构建一套关于上下文工程/管理的通用方法:写入 (Write)、选取 (Select)、压缩 (Compress) 和隔离 (Isolate)。这套框架在传统的 LLM 应用/系统开发中依然有效,但在我们迈向更复杂的 Agentic System 时,一些更为本质的挑战开始浮现。我们需要深入其中一些细节以构建更高效的上下文工程。
本篇让我们聚焦在 Context Select 领域,探讨目前 Agent/Context Engineering 中最关键的演进之一:从开发者主导的“预计算上下文 (Pre-computed Context)”,转向由 Agent 主导的“即时上下文 (Just-in-Time Context)”。
2. The Shift: From Pre-computed to Just-in-Time¶
在上一篇博客中提到的 Context Select 环节,我们最熟悉的范式莫过于 RAG (Retrieval-Augmented Generation)。传统 RAG 的工作流程是:用户输入 Query → 检索系统自动进行 embedding 匹配 → 将结果注入上下文 → LLM 基于这些上下文进行推理。
这个流程中,LLM 是上下文的被动接收者。它无法决定自己需要什么信息(检索系统决定),也无法判断检索系统返回的内容是否真正有用。检索系统基于语义相似度的假设是:"解决问题所需的信息,与问题本身在向量空间中距离相近。" 这个假设一定正确吗?
对于"公司的休假政策是什么?"这类知识查询,这个假设是成立的。然而,当我们转向复杂的 Agent 任务时,这个假设会迅速失效。例如,修复一个 Bug 可能需要查看其报错日志,但造成 Bug 的原因可能隐藏在一个语义上毫无关联的配置文件中——它们的 embedding 向量可能相距甚远,但在逻辑上却存在因果关系。
尽管 GraphRAG 等技术通过引入结构化关系增强了检索系统的能力,但其本质仍未脱离 Pre-computed 范式。这种试图 “在推理前穷尽所有联系” 的静态索引策略,使得系统性能高度耦合于底层知识图谱的质量,始终未能突破预计算模式的固有局限。
这就引出了 Just-in-Time (JIT) Context 的核心哲学:让 LLM 从上下文的被动接收者,转变为主动探索者。
2.1 Passive vs Active¶
理解这个转变的关键在于区分两个正交的维度。Agentic 和 Semantic 是两个不同的维度。例如,传统的 RAG 到 Agentic RAG 的转变并不是从基于语义的搜索(Semantic)升级为了更强的检索算法,而是决策机制的转移,Agent 从被动接收信息变为主动获取信息。如下图所示:

维度一:谁在决策?
- 被动模式:检索系统基于预设规则自动触发,LLM 只能接收检索系统返回的上下文。
- 主动模式:LLM 自己判断需要什么信息,决定何时、如何获取。
维度二:用什么方法检索?
- Semantic search(传统 RAG 中常用的向量相似度)
- Exact match(grep、关键词搜索)
- Structural navigation(ls、文件遍历)
- API 调用、数据库查询等等。
这两个维度是正交的。在主动模式下,Agent 完全可以根据任务上下文,自主决定是调用向量检索来获取模糊语义,还是使用 grep 进行精确的代码定位。所以重点是:Agentic 描述的是"谁在决策",而非"用什么方法检索"。
我最开始的章节标题是 From Semantic to Agentic,反复琢磨觉得它不够正确,它们其实并不是同一个维度的概念。出现这种误读的主要原因是把传统 RAG 和 Semantic Search 等价了,认为传统 RAG 的侧重点是 Semantic 而非 Pre-computed。
传统 RAG 的局限不在于 "语义搜索" 本身,而在于 LLM 缺乏对检索过程的控制权。当我们赋予 LLM 主动探索的能力后,它理想情况下可以根据任务需求灵活选择最合适的检索策略 —— 有时是语义匹配,有时是精确搜索。从“预计算”的枷锁中解放,转向基于任务需求即时构建的 Just-in-time Context。
2.2 JIT Context: References as Context¶
要实现 JIT Context,一个前置问题是:Agent 如何知道信息可能在哪里,而不必先把信息本体塞进上下文窗口?
就像人类的认知系统并不会背诵整个图书馆的内容,而是依赖索引和目录。在 JIT Context 中,这意味着我们需要引入轻量级标识符例如 文件路径、API 端点、网页链接 作为引用。Agent 从而能通过引用了解信息储存于何处,并在运行时按需将数据动态加载到上下文窗口中。
基于第一章提到的注意力预算(即上下文窗口的有限容量及模型对输入 token 的关注度分配),这些引用是极低注意力成本的 token,但提供了极高密度的推理线索。例如,tests/ 文件夹下的 test_utils.py 和 src/ 下的同名文件,对 Agent 而言隐含了完全不同的用途。文件夹层级结构、命名惯例和时间戳等元信息构成了 Agent 对外部世界的"地图",使其能够在不加载具体内容的情况下进行全局规划。
2.3 JIT Context: Progressive Disclosure¶
有了地图,Agent 就能以渐进式披露的方式获取信息。每一次交互都会产生为下一次决策提供信息的上下文:文件大小暗示复杂性(是否需要截断,是否需要用 sub-agent 进行上下文隔离?);命名惯例暗示目的(例如 xx_test 在 Google 内部统一代表单元测试)。Agent 可以逐层构建理解,仅在上下文窗口中保留必要内容,并利用笔记策略(后文中会提到,本质上就是上一篇博客中的 Write 方法)实现额外的上下文持久性。这让 Agent 能聚焦于与问题直接相关的 token,而非被海量可能无关的信息淹没。
以 Claude Code 常用的工具为例:
- List (
ls): 查看目录结构,根据命名和层级推断潜在的相关模块 - Search (
grep): 基于特定的变量名或错误码进行精确匹配 - Read (
read_file): 只有当 Agent 通过推理确认目标包含关键逻辑时,才会将其内容真正加载到上下文中
这种探索是由逻辑链条而非语义相似度驱动的:Agent 从 A 追踪到 B,是因为它读懂了代码间的调用关系,而非因为两段代码的 embedding 向量相似。相比于 Semantic Search 可能引入大量“语义相关但逻辑无关”的噪声,这种主动探索能显著降低上下文污染,从而减少幻觉,聚焦于解决问题的最小完备 token 集合。(由于上下文窗口中的每一段内容都会影响模型的注意力分配,减少无关信息也能降低模型被误导而产生幻觉的风险)
2.4 The Trade-off & Hybrid Strategy¶
JIT Context 虽然提升了上下文的精准度,但也引入了不可忽视的工程代价:
延迟问题:多次工具调用的交互不可避免地增加了响应时间。Pre-computed 模式下,向量相似度的计算本身非常迅速,并且检索系统可以并行进行检索;JIT 模式下,探索通常表现为串行的决策-执行循环(类似 ReAct 模式),这在单 Agent 场景中不可避免地增加了延迟。
工程复杂性:JIT 模式我们需要为 Agent 设计恰当的工具集和启发性指令。指令不能过于硬编码(会退化为 if-else 工作流),也不能过于模糊(Agent 无法确定具体操作)。这需要工程师具备优秀的技术直觉和 Agent 工程积累(这对工程师的技术直觉提出了较高要求)。
因此,在工程实践中,混合策略 往往是最佳选择:
- Push (Static Preload): 将高频、通用的上下文直接预加载到窗口中。例如 Claude Code 的
CLAUDE.md(项目规范、开发偏好,回复用中文还是英文)。这些信息几乎每次任务都会用到,预加载可以节省 Agentic 探索的成本。 - Pull (Just-in-time Exploration): 对于任务相关的具体信息,提供丰富的工具集,让 Agent 根据需求自主探索。探索时可以灵活选择方法:semantic search、grep、ls、API 调用等。具体选择取决于工具最适合当前的任务上下文(目前的发展呈现两种不同的趋势,可以参考 Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens)。
这种设计的本质是:用预加载解决一定会用到的上下文,用及时探索解决可能会用到的上下文。 它既避免了盲目预加载带来的上下文污染,又减少了不必要的探索开销,是当前构建高效智能体系统的不错选择。
Do the simple thing that works.
如果一辆自行车足以解决问题,我们就不必发明宇宙飞船。
这是 Anthropic 的某个 slogan,我很喜欢,也觉得挺值得思考的。因为许多"精巧"的设计似乎会被 LLM 性能的增长粗暴的碾压。关于工具的选择(例如在 Coding Agent 中是用 grep 还是 Vector Search),业界目前存在不同声音。尽管有观点认为纯 grep 策略在 Token 消耗上极其昂贵(参考 Milvus blog),但 Anthropic 似乎更倾向于确定性更强的工具。
结合这个 Slogan,也许一个简单的、确定性的 grep,配合 Agent 强大的逻辑推演,比一个精巧但黑盒的向量检索更符合 "Simple & Robust"?
3. Effective JIT Context Engineering¶
探索的自由度与上下文的信噪比之间存在内在张力
JIT Context 的本质是放权:允许 Agent 通过多步推理和渐进式试错来获取信息。然而,这种自由伴随着代价,即探索中的过程噪音。
在 Pre-computed 范式下,上下文是静态的(Static Top-K Chunks);而在 JIT 范式下,上下文是动态生长的。Agent 的每一次工具调用,都会在上下文窗口中留下不可磨灭的过程噪音。
回顾第一章的核心论点:上下文是边际收益递减的有限资源。JIT 的理想是“精准拉取当前所需”,但讽刺的是,为了达到这种精准,Agent 往往需要产生大量试探性的中间 token。参考一个典型的 JIT 代码探索序列:
Agent: [调用 ls src/] → 返回 20 个文件名
Agent: [推理] 基于命名,auth.py 可能相关
Agent: [调用 grep "login" src/auth.py] → 返回 15 行匹配
Agent: [推理] 第 42 行的函数看起来是入口
Agent: [调用 read_file src/auth.py -n 40-60] → 返回 20 行代码
Agent: [推理] 发现它依赖 utils.py
Agent: [调用 read_file src/utils.py] → 返回 200 行代码
...
每一步都是合理的。但当 Agent 最终定位到问题根源时,上下文中已经塞满了"探索路径"的完整记录(Tool traces)。那些早期的 ls 输出、 grep 结果、最终未被采用的代码片段,它们对于"做出当前决策"几乎没有价值,却占据着宝贵的注意力预算。
当 Agent 最终定位到 utils.py 中的 Bug 时,上下文窗口中已堆积了大量早期的 ls 列表和 grep 结果。这些信息在 “探索阶段” 是必要的路标,但在 “决策阶段” 却沦为占据注意力预算的无用 token 集合。
Tip
💡有人可能会思考,ls 和 grep 的输出真的毫无价值了吗?
显然不是。在解决相关联的后续子任务时,这些信息可能再次被访问(即存在"时间局部性")。
因此,我们可以借鉴计算机体系结构中的缓存管理思想来重构上下文治理:
- 懒淘汰:我们不必在工具执行完的瞬间立即清除结果。可以基于任务完成情况,容忍其在上下文中短暂停留,直到确认当前任务完成再进行管理。
- 分级存储:淘汰并不意味着直接删除,我们把最重要的信息保留在上下文(Cache)中,这些可能不再重要的信息可以写入到外部文件系统中。
当信息从上下文窗口中被"淘汰"时,我们应当将其 Offload(卸载)到外部存储(如写入到一个持久化的文件或记忆数据库中),而不是直接销毁。这也是后文要讨论的 Write 策略的理论基础。
这便是 JIT 的代价:Agent 越智能、探索越深入,Agent 系统的熵(混乱度,上下文窗口用量)积累就越快。
即使不是长程问题,若缺乏有效的治理机制,宝贵的上下文窗口将迅速被过程噪音填满。因此,我们需要引入一套 “上下文代谢机制”来实现高效的 JIT Context Engineering。这通常涉及三个维度的工程实践:Write (卸载)、Compress (压缩)、Isolate (隔离)。
3.1 Compress¶
Compress(压缩) 是最直接的代谢策略:当上下文累积到一定阈值时,通过有损变换来置换空间。在工程实践中,目前主要分为 基于模型的语义压缩 和 基于规则的结构化剪枝。
3.1.1 基于模型的语义压缩
主流 Coding Agent 普遍实现了这一功能,典型做法是将完整历史传给模型进行摘要。例如,总结并保留架构决策、未解决的错误和实现细节,同时舍弃冗余的工具输出或消息。
这是 Coding Agent(如 Claude Code,Codex)的主流做法。当上下文达到阈值,系统调用 LLM 对历史交互进行摘要。其核心在于语义重构:保留架构决策、未解决的 Error 和关键路径,舍弃冗余的工具输出。同时,为了避免压缩影响任务连续性,我们可以强制保留最近的一段上下文,以减轻压缩对任务的影响。
举个之前博客使用过的例子,Cognition AI 在 Devin 中会使用专门的上下文压缩大模型进行压缩。
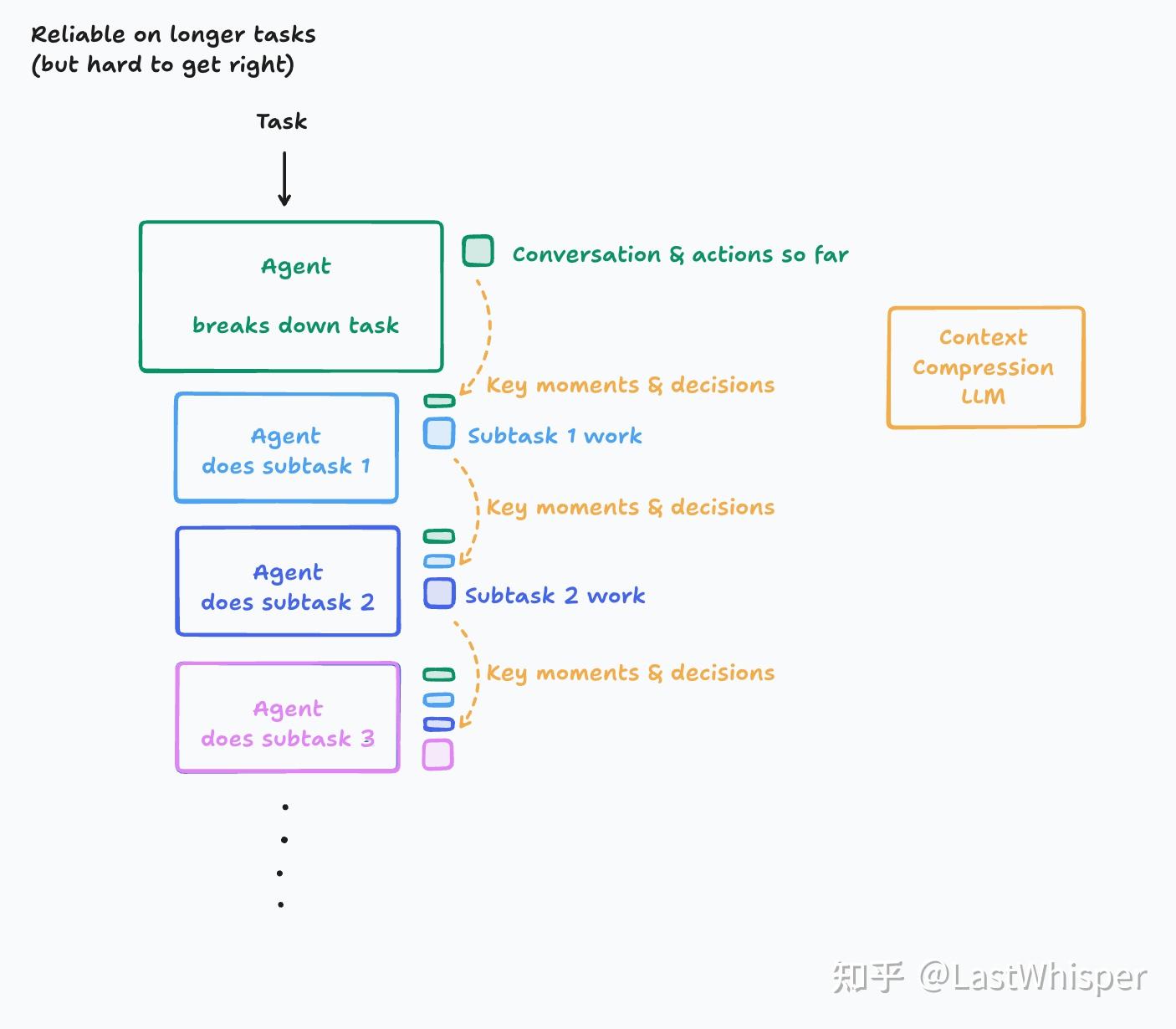
上下文的压缩本身也是一种艺术。压缩的核心挑战在于取舍。过于激进的压缩可能丢失"当时看似无关、事后却关键"的上下文。这需要在具体任务上仔细调优,Anthropic 建议先最大化召回率(确保不丢失关键信息),再逐步优化精确率(减少冗余)。这种顺序的逻辑是:漏掉关键上下文的代价通常高于保留少量冗余。Cognition AI 等厂商甚至会为此 Fine-tune 专用的 compress model,以在压缩率和保真度之间寻找最佳的平衡。
3.1.2 基于规则的结构化剪枝
语义压缩虽然灵活,但具有黑盒属性且成本较高。Anthropic 近期推出的 Context Editing 则代表了一种确定性的、轻量级的压缩范式。其核心逻辑是回溯性清理:系统自动清除历史中较早的 Tool Outputs 或 Thinking Blocks,仅保留一个占位符。不仅仅是简单的删除,而是将上下文按规则进行了简单的分类:
- 热数据:保留最近 N 轮交互的完整细节(可以由用户控制),维持短期记忆的连贯性。
- 冷数据:将过时的数据(Tool Traces & Thinking Blocks)清理并折叠为占位符。结合 Memory Tool(写入到记忆目录中),Agent 仍保留了“知道自己曾经知道”的元认知,必要时可通过 JIT Context 重新加载。
Context Editing 的具体效果如下图所示,这里只是简单的示意,展示了剪枝后腾出了大量的上下文。

我之前的博客涉及过 Prompt Caching。引入 Context Editing 会带来一个棘手的副作用:它会破坏 Prompt Caching 的前缀匹配机制。绝大多数 Prompt Cache 依赖于静态的前缀 (Prefix Match)。一旦我们在历史上下文中“挖洞”(删除中间的 Tool Output),后续所有的 Token 序列都会发生位移,导致缓存失效,从而显著增加推理成本和延迟。原理如下图所示:

这是一个典型的 Tradeoff,因此,你需要自己权衡“提示词缓存”和“上下文窗口可用性”之间的优先级。Anthropic 对此提供了一个简单的配置项 clear_at_least。仅当被清除的 Token 数量超过阈值(即节省的上下文空间的价值 > 重复计算 Cache 的成本)时,才执行压缩。
这种精细化的权衡,也标志着 Context Engineering 正从简单的“提示词技巧”,进化为一种系统工程。
3.2 Write¶
如果说 Compress 是“消化”,在窗口内通过有损压缩换取空间;那么 Write (写入) 则是“外化”,将信息完整卸载到窗口之外的持久化存储中。
Scratchpad(草稿纸) 是最常见的 Write 模式。Agent 在任务执行过程中主动维护一个结构化的笔记文件(e.g. Plan.md),记录关键发现、待解决问题、当前进度。这些信息转移到文件系统后不再占用上下文窗口,但可按需重新加载。
Write 策略的真正威力,在于它与 Context Editing 的结合,构成类似操作系统中的 Swap (内存交换)机制。如图所示,在上下文管理系统可以在清除某段“热上下文”之前,Agent 主动将其中的高价值信息(如代码分析结果、测试日志)写入“冷存储”(文件系统或专用记忆目录)中实现内存交换。

这种“先写入,后清除”的 Swap 模式,完美契合 JIT Context 的哲学:Agent 依靠引用(文件路径)而非全文来维持记忆。并且能突破上下文窗口的限制。Compress 存在理论上限(多次压缩会导致信息失真),且总会占用一定的 Token。而 Write 实现了“上下文的无限延伸”。即使在长程任务中,上下文窗口被重置,或者 Agent 发生崩溃重启,保存在磁盘上的“外化记忆”依然能确保任务的断点续传。
3.3 Isolate¶
Isolate(隔离) 是架构层面的代谢策略:通过子代理的独立上下文窗口,将探索时大量 Select 的开销分散到多个隔离的处理单元中。
当主代理需要探索某个复杂的子问题时,它可以派出一个子代理在独立的上下文中完成探索。子代理可能累积数万 token 的过程噪音,但这些 token 被隔离在其独立上下文中——主代理只接收精炼后的结论。同时,隔离在某些情况下会让输出/搜索的结果更纯净,避免冲突的信息在上下文中影响输出效果。
以 Coding Agent 场景为例,某些情况下 JIT Context 需要了解当前代码库中某几个模块的具体作用,这些模块可能涉及上万行的代码,可以使用多个子代理分别进行分析与总结,把分析的结果写入到对应的文件系统中,仅返回对应的文件路径,主 Agent 可以通过工具调用在不污染上下文窗口的情况下轻松的获取对这几个模块的探索结果。
这类似于组织中的层级汇报:基层员工处理大量细节,向上级仅提交摘要和结论。子代理架构将这种'信息压缩上报'的模式复制到了 Agent 系统中。
Isolate 在我之前的博客中讲的更为细致一些:
结论是:子代理架构在复杂任务上显著优于单一 Agent。其本质原因正是隔离所带来的"分布式 Select & Compress & Write",每个子代理独立处理自己的过程噪音,返回结论时本身就可以执行压缩和写入策略,主代理只需要整合高密度的结论。
3.4 Summary¶
至此,我们构建了一套完整的 Effective JIT Context Engineering 框架。结合第二章的摄入(Select)策略,我们可以将 JIT Context Engineering 划分为两个阶段:
| Stage | Strategy | Core Action |
|---|---|---|
| 摄入 | References + Progressive Disclosure | Agent 按需拉取信息 |
| 代谢 | Compress / Write / Isolate | 管理探索产生的过程噪音 |
最佳实践组合:主代理通过 Isolate 分发任务 -> 子代理探索并 Write 结论至文件 -> 主代理读取结论并定期 Compress 自身历史。
JIT Context Engineering 是让 Agent 从“信息的被动接收者”进化为“上下文的主动管理者”。如果只关注检索(摄入)而忽略治理(代谢),系统终将因上下文肥胖而导致推理能力崩溃。只有建立起健康的管理机制,Agent 才能在长期、复杂的任务中保持高效。
4. Conclusion¶
回顾全文,一个核心 insight 逐渐清晰:上下文工程的本质是信息密度的优化。
无论是 JIT Context 的按需拉取、Compress 的摘要压缩、Write 的持久化存储,还是 Isolate 的上下文隔离,它们都在服务同一个目标:在每一步推理时,为模型准备一份"恰到好处"的上下文:既不缺失关键信息,也不淹没于冗余噪声。
这篇博客尝试将 JIT Context Engineering 拆解为两个阶段:摄入(References + Progressive Disclosure)与代谢(Compress / Write / Isolate)。前者让 Agent 能够主动探索并获取解决问题的关键信息;后者则管理探索过程中不可避免产生的上下文膨胀。缺少代谢机制的 JIT Context System,就像一个只吃不排的生物体——短期内可能正常运转,但最终必然崩溃。
我个人非常喜欢 Context Engineering 这个概念。参考上一篇博客,我引用了 2023 年左右 OpenAI 的一张图,展示了性能优化的两个维度:基础模型与上下文。当模型能力跨过某个阈值后,上下文工程的重要性愈发凸显。而且它具有一定的 Model Agnostic 特性——这让我更愿意在这个方向上持续探索。

我目前一个初步的观察是:目前 Select 相关的实践(如 Agentic RAG / JIT Context)发展相对成熟,而 Compress / Write / Isolate 等代谢机制的高效上下文工程实践仍在早期阶段。如果未来这几个部分都能达到足够的成熟度,长时运行的 Coding Agent 的瓶颈可能从"上下文管理"转移到"任务分解与目标定义"。换句话说,Agent 的能力边界,取决于你的思维边界。Agent 能做多少,可能取决于你能多清晰地描述你想要什么。
最后,用两个思考收尾。
Do the simple thing that works. 这是 Anthropic 的一句 slogan,我在写这篇博客时反复想起它。Context Engineering 的演进,大概也会从具体的工程实践中生长出来,而非从宏大的理论框架向下推演。先做简单有效的事,再逐步迭代。
"♪ The Line": Will they still let me over, if I cross the line? 这是某个动漫一首歌中的一句歌词。我常写"模型能力跨过了某个阈值",但跨过之后会发生什么?没人真正知道。Agent 的能力边界终将跨过某条 line,Will they still let Agent over, If Agent cross the line?
References¶
- [1] Anthropic: Effective context engineering for AI agents
- [2] Anthropic: How we built our multi-agent research system
- [3] Anthropic: Building agents with the Claude Agent SDK
- [4] Anthropic: Managing context on the Claude Developer Platform
- [5] Claude Docs: Context editing
- [6] Claude Docs: Memory tool
- Blog: context rot
- Milvus blog: Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
- My Blog: Context Engineering,一篇就够了。
- My Blog: Multi-Agent System,一篇就够了。
- My Blog: Prompt caching,一篇就够了。
- Music: ♪ The Line